Ver en castellano
Praat resources
If you work with spoken language, you've undoubtedly worked with Praat. This page contains a few resources to make life with the program a bit easier.
I've also prepared some tutorials for using Praat (in Spanish).
Scripts | Syntax Highlighting | Icons
Praat scripts
Massive Speech Corpus Tool - Recursive (MaSCoT-R)
Version 3.2 (17 August 2017)
This new version of MaSCoT makes working with large numbers of recordings far easier and more efficient -- instead of requiring the user to load and process recordings one at time, it automatically processes the recordings in all the subdirectories of a user-specified root folder.
If you wish to use this recursive version of MaSCoT on a single recording, temporarily place the audio and text grid files in their own folder and process that folder.
Older versions
| Licensed under the GNU GPL v3 . |
Massive Speech Corpus Tool (MaSCoT)
Version 2.5
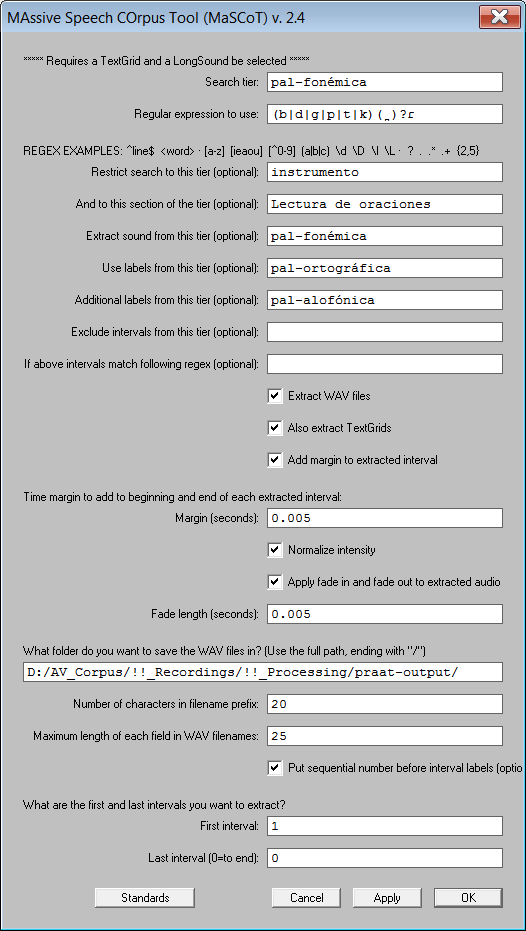
MaSCoT is a tool developed to facilitate searching, extracting and analyzing information contained in large, richly-annotated speech corpora developed in Praat.
MaSCoT takes a TextGrid and a LongSound object as input, and allows users to perform sophisticated searches on these objects using regular expressions and multiple-tier conditions. MaSCoT's output always includes a report detailing the search results and the search and extraction options used. Optionally, it can also extract and label TextGrid fragments (to individual TextGrid files) and/or audio (to individual WAV files) from any tier related to the search results.
To get an idea of MaSCoT's capabilities, download the TextGrid and WAV file from my Praat tutorial, open them in Praat (the WAV must be opened as a LongSound file), and execute MaSCoT (open it as a script from within Praat). With its default settings, MaSCoT does the following:
- Searches the phonemic transcription tier (pal-fonémica) for all words containing any of /b d g p t k/ followed by an alveolar tap /ɾ/, with an optional dental diacritic ( ̪) between them.
- Limits the search to speech elicited through the reading of a list of sentences (the Lectura de oraciones section of the instrumento tier).
- Extracts the sound from the section of the recording corresponding to each word meeting the search criteria, and saves it to individual WAV files. When using a hierarchically-segmented TextGrid, with the largest segments on top (e.g. instruments) and their smallest sub-segments at the bottom (e.g. individual phones), it is possible, for example, to search for individual phonemes and extract the sound of the entire syllable they are located in, or indeed the entire word or utterance.
- Extracts the TextGrid from the same section of the recording as the sound.
- Labels the WAV and TextGrid files with the labels from the orthographic transcription tier (pal-ortográfica), as well as other information related to the search.
- Logs the search criteria and results to a text file.
Some potential applications of MaSCoT
- Extract all instances of a given class of items: voiceless fricatives preceding front vowels, syllables with the structure CCCV, fricative allophones of /tʃ/, utterances with a given intonation pattern -- your annotation is the only limit.
- Compare the effects of stylistic variables. If different language use styles were elicited from informants (e.g. a controlled style from the reading of word lists, and a spontaneous style by way of an interview), assign each of these to a separate section of a tier called "Instruments", and then perform the same search separately on each section.
- Study the effects of POS on production. Duplicate a tier segmented at the word level and annotate it with words' POS categories. Then separately extract words from open classes and closed classes, or proper nouns and common nouns, etc.
- Study lexical diffusion hypotheses. If you believe that a certain lexical set behaves differently from other, similar words, search for and extract the members of the set by entering them in MaSCoT's regular expression box, using the syntax (word1|word2|word3|...|word100).
Older versions
MaSCoT 2.2
MaSCoT 1.7 with Spanish interface (last localized version)
| Licensed under the GNU GPL v3 . |
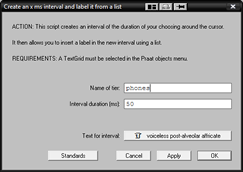
Create n ms interval and add label from menu
 Download (in English)
Download (in English)
Download (in Spanish)
This script creates an interval of a user-defined duration around the current cursor position, and then lets the user add a label to the segment by selecting it from a menu. It's especially useful in the following cases:
- When you need to work with exact durations (e.g. 25 ms).
- When the same labels must be inserted over and over again. In this case, the script doesn't just save time -- it also eliminates the possibility of introducing typing errors or deviations from your canonical set of labels.
- When you need to insert phonetic or other symbols which are difficult to input through the keyboard (though in this situation, I recommend you try Lenz if you use Windows).
As far as the backend goes, this script is mainly notable because it implements an alternative routine for creating intervals (insertLabel) which, unlike Praat's built-in routine, doesn't add unwanted segment boundaries at the edge of the screen or elsewhere.
Note that the script file is in UTF-8. This makes it possible to use IPA symbols, but it also means the file must be edited in a Unicode-compatible text editor (e.g. Notepad++, UltraEdit, Kate, gedit) or directly in Praat's script window.
Download (in English)
Download (in Spanish)
| Licensed under the GNU GPL v3 . |
Syntax highlighting file for Notepad++
NEW (31 may 2014): Version 2.1!
This file allows the open-source text editor Notepad++ to highlight the various elements of Praat scripts (delimiters, operators, commands, etc.) with different types of formatting, thus making them vastly easier to work with.
Version 2.0, released on May 25, 2014, is a complete rewrite. It includes most of Praat's commands, including many (but not all!) of the new ones introduced with the updated scripting language. It also fixes a longstanding bug that affected code folding.
Version 2.1 changes how multi-word commands are treated, to make highlighting work with the new colon-based syntax. Now, Your favorite command... and Your favorite command: will be treated identically.
To use it, extract the file called userDefineLang.xml from the linked ZIP file. In Windows Vista, 7 and 8, place the extracted .xml file in C:\Users\YourUserName\AppData\Roaming\Notepad++\, restart the program, and you're ready to go. In Windows XP, the file should go in something like C:\Documents and Settings\YourUserName\Application Data\Notepad++\. If nothing else works, type %APPDATA%\Notepad++ in the run box (WIN+R) and the folder you should copy the .xml file to will open automatically.
The Praat syntax highlighting will be applied to any file ending in .praat, .script, .psc, .praat_script, .praatscript, .praat-script and .praat-batch.
| Licensed under the GNU GPL v3 . |
Icons for Praat files
Download in ICO format (Windows) · Downoad in PNG format (Linux)
I've made a set of different colored Praat icons that can be assigned to the various types of Praat files (TextGrids, tables, scripts, etc.) to help keep them straight.
| Licensed under the GNU GPL v3 . |