This page in English
Recursos de Praat
Si trabajas con el lenguaje oral, indudablemente has utilizado Praat. Esta página contiene algunos recursos que pueden hacer la vida con este programa un poco más llevadera.
También he creado algunos tutoriales sobre el uso de Praat.
Scripts | Destacado de sintaxis | Íconos
Scripts de Praat
Massive Speech Corpus Tool - Recursive (MaSCoT-R)
Versión 3.2 (17.07.2017)
NOTA: La versión más reciente está disponible en GitHub.
Esta nueva versión de MaSCoT hace más fácil y eficiente el trabajar con grandes números de grabaciones. En vez de obligar al usuario a cargar las grabaciones una por una, esta versión del programa procesa todas las grabaciones que se encuentren en las subcarpetas de una determinada carpeta raíz.
Si deseas procesar una sola grabación con esta nueva versión, colócala temporalmente en una carpeta propia y luego procésala allí.
Versiones antiguas
| Publicado bajo la licencia GNU GPL v3 . |
Massive Speech Corpus Tool (MaSCoT)
 Versión 2.5
Versión 2.5
(Más abajo está disponible una nueva versión de MaSCoT que procesa los subdirectorios de una determinada carpeta raíz de manera recursiva).
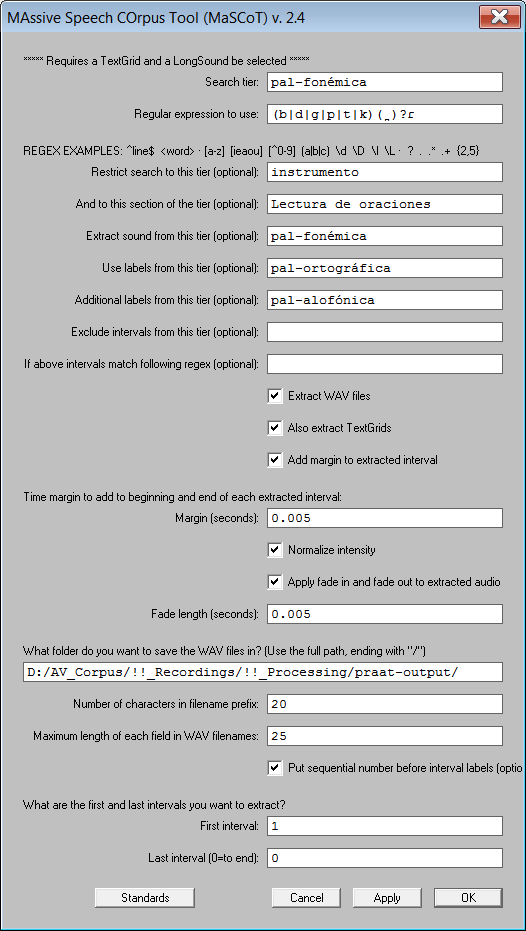
MaSCoT es una herramienta que facilita la búsqueda, extracción y análisis de la información que contienen los corpora orales con anotaciones ricas que se han desarrollado con Praat.
A partir de un TextGrid y un objeto LongSound, MaSCoT permite realizar sofisticadas búsquedas con expresiones regulares y condiciones que dependen del contenido de los diversos tiers. Para toda operación, MaSCoT genera un informe que incluye los resultados de la búsqueda y las opciones de búsqueda y extracción que se emplearon. Además, puede extraer y etiquetar fragmentos de TextGrids y extractos de audio (los cuales se guardan en archivos individuales) de cualquier tier que tenga relación con los resultados de la búsqueda.
Para hacerse una idea de lo que se puede hacer con MaSCoT, baje el TextGrid y el archivo WAV del tutorial, ábralos en Praat (el archivo WAV debe abrirse como LongSound), y ejecute MaSCoT (como un script, dentro de Praat). Con sus valores preconfigurados, MaSCoT hace lo siguiente:
- Busca, dentro del tier de transcripción fonémica (pal-fonémica), todas las palabras que contengan los fonemas /b/, /d/, /g/, /p/, /t/ o /k/ seguido optativamente de un diacrítico dental ( ̪), y luego de un vibrante simple /ɾ/.
- Limita la búsqueda al habla elicitada mediante la lectura de oraciones (es decir, la sección Lectura de oraciones del tier instrumento).
- Extrae el sonido de las secciones de la grabación que corresponden a las palabras que arroja la búsqueda, guardándolo en archivos WAV individuales. Cuando se usa un TextGrid jerárquicamente segmentado, con los segmentos más amplios arriba (e.g. los instrumentos de elicitación) y los sub-segmentos más pequeños abajo (e.g. fonos individuales), es posible buscar fonemas individuales y extraer el sonido de toda la sílaba, palabra o frase en que ocurren.
- Extrae la sección del TextGrid que corresponde al sonido que se extrajo.
- Etiqueta los archivos WAV y TextGrid con información recuperada del tier de transcripción ortográfica (pal-ortográfica), y alguna otra información relacionada con la búsqueda.
- Registra los criterios y resultados de la búsqueda en un archivo de texto.
Posibles aplicaciones de MaSCoT:
- Extraer todas las instancias de un determinado fenómeno: oclusivas áfonas que ocurren ante vocales anteriores, sílabas con la estructura CCCV, alófonos fricativos de /tʃ/, enunciados con un determinado patrón de entonación... las anotaciones del corpus son el único factor limitante.
- Estudiar los efectos de variables estilísticas. Si se elicitan distintos estilos de producción lingüística a los informantes (e.g. un estilo controlado mediante la lectura de una lista de palabras, y un estilo espontáneo a través de una entrevista), se puede asignar cada estilo a una sección distinta de un tier (por ejemplo, "instrumentos"), y luego realizar las mismas búsquedas y análisis en cada sección por separado.
- Analizar los efectos de la categoría gramatical en la producción oral. Si se segmenta un tier a nivel de palabras individuales, y luego se anota en los intervalos la categoría gramatical de cada palabra, se puede extraer y contrastar lo que sucede con las palabras de clases léxicas abiertas y cerradas, con los sustantivos frente a los verbos, etc.
- Probar hipótesis respecto de la difusión léxica. Para determinar si las palabras que pertenecen a un determinado conjunto léxico se comportan de manera distinta que otras, se puede buscar y extraer los miembros del conjunto, ingresándolos en el cuadro de expresiones regulares de MaSCoT con la siguiente sintaxis: (palabra1|palabra2|palabra3|...|palabra100).
Versiones antiguas
MaSCoT 2.2
MaSCoT 1.7 con interfaz en castellano (última versión localizada)
| Publicado bajo la licencia GNU GPL v3 . |
Crear un intervalo y etiquetarlo mediante un menú
 Bajar (en castellano)
Bajar (en castellano)
Bajar (en inglés)
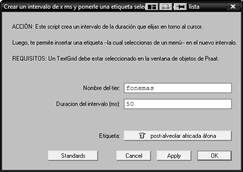
Este script crea un intervalo de la duración que elijas en torno al cursor. Luego, te permite insertar una etiqueta --la cual seleccionas de un menú-- en el nuevo intervalo. Es especialmente útil en los siguientes casos:
- Cuando hay que trabajar con duraciones precisas (e.g. 25 ms).
- Cuando se deben insertar las mismas etiquetas repetidas veces. En este caso, no sólo se ahorra trabajo, sino que se elimina la posibilidad de introducir errores de tipeo.
- Cuando se trata de insertar símbolos fonéticos (o de otra índole) que difícilmente pueden ingresarse a través del teclado (aunque para estos fines, recomiendo utilizar Lenz, siempre que uses Windows).
En cuanto a lo que sucede tras bambalinas, el script es notable principalmente por el hecho de que implementa una nueva rutina para crear intervalos (insertLabel), la cual --al contrario de la rutina incorporada en Praat-- no agrega intervalos no deseados en el borde de la pantalla visible ni en otros lugares.
Es importante señalar que el archivo está en formato UTF-8 (una codificación de Unicode). Esto permite que contenga símbolos fonéticos, pero a la vez, obliga a editar el script en un editor de textos compatible con Unicode (e.g. Notepad++, UltraEdit, Kate, gedit) o en la ventana de scripts de Praat.
Bajar (en castellano)
Bajar (en inglés)
| Publicado bajo la licencia GNU GPL v3 . |
Archivo de destacado de sintaxis para Notepad++
NUEVA VERSIÓN: 2.1 (31 de mayo de 2014)
Descargar la versión 2.1
Este archivo permite que el editor de textos Notepad++ destaque los diversos elementos de los scripts de Praat (delimitadores, operadores, comandos, etc.) con distintos colores, facilitando la programación de manera importante.
La versión 2.0, publicada el 25 de mayo de 2014, se escribió a partir de cero. Incorpora la mayoría de los comandos de Praat, incluyendo muchos de los de la nueva versión de su lenguaje de scripting.
La versión 2.1 cambia la manera de que se tratan los comandos compuestos de más de una palabra, para lograr que el destacado funcione correctamente con la nueva sintaxis de Praat. Ahora, Tu comando favorito... y Tu comando favorito: son tratados de manera idéntica.
Para utilizar el destacado de sintaxis, extrae el archivo llamado userDefineLang.xml del archivo ZIP. En Windows Vista, 7 y 8, coloca el archivo .xml en C:\Usuarios\TuNombreDeUsuario\AppData\Roaming\Notepad++\, reinicia el programa, y todo debería funcionar. En Windows XP, coloca el archivo .xml en algo así como C:\Documentos y configuración\TuNombreDeUsuario\Datos de programa\Notepad++\. Si lo anterior no funciona, tipea %APPDATA%\Notepad++ en la barra de direcciones de Windows Explorer y copia el archivo .xml a la carpeta que aparece.
El destacado de sintaxis de Praat se aplicará a todos los archivos terminados en .praat, .script, .psc, .praat_script, .praatscript, .praat-script and .praat-batch.
Versiones antiguas: 1.1 ·1.0 · 2.0
| Publicado bajo la licencia GNU GPL v3 . |
Íconos para archivos Praat
Bajar en formato ICO (Windows) · Bajar en formato PNG (Linux)
He creado una serie de íconos de Praat de distintos colores que pueden asignarse a los diversos tipos de archivos que produce Praat (TextGrids, tablas, scripts, etc.) para que sea más fácil distinguirlos.
| Publicados bajo la licencia GNU GPL v3 . |